
The first AI
takeoff tool.
Construction estimators were drowning in manual takeoffs. We shipped an AI that found the rooms, doors, and windows in their drawings — and earned their trust by showing every pixel of its work.
Estimators were drowning
in their most important task.
A takeoff is the act of counting and measuring every door, window, wall, and room across hundreds of construction drawings — so an estimator can price a bid. It is the first thing that happens on a project, the last one to finish, and the one most prone to error. Miss a bathroom on page 47, and the entire bid is wrong.
I worked the trade
before I worked the screen.
No personas, no whiteboard frameworks, no opinion-led redesign. I rode shotgun with six estimators across three GC firms for a week, traced a single winning bid backwards keystroke-by-keystroke, then co-sketched the fix on tracing paper laid over their own drawings. The screen came last.
Ride-along — a week on the estimator's desk
Bid-back trace — reverse-engineer one winning bid
Co-sketch — design on top of their drawings
Three frictions blocking adoption
Black-box AI
No first-class drawing tools
Cognitive overload at the canvas
From signals to design moves
Each friction got pressure-tested through the same loop: paper sketches → low-fi Figma → clickable prototype with 5 estimators → revise, or kill. Roughly half the ideas died here. What survived became three principles that everything in the redesign answers to.
The system underneath the work.
A small, opinionated system: one display face, one workhorse sans, one mono for instrumentation. Two greens that carry every signal of trust — one for the everyday, one for the dark surfaces. Tokens, not decisions, all the way down.
The bid gets out
before the
competitor’s does.
Three KPIs we set day-one and held to. None of them moved the way they did because the AI got smarter — they moved because estimators finally believed the numbers it returned.
Top-100 commercial GC
Day 90 follow-up
An AI that
shows its work.
Rolled out behind a feature flag over 6 months — internal → 5 design partners → 25 firms → public beta. Three surfaces did the heaviest lifting; the rest fell out for free.
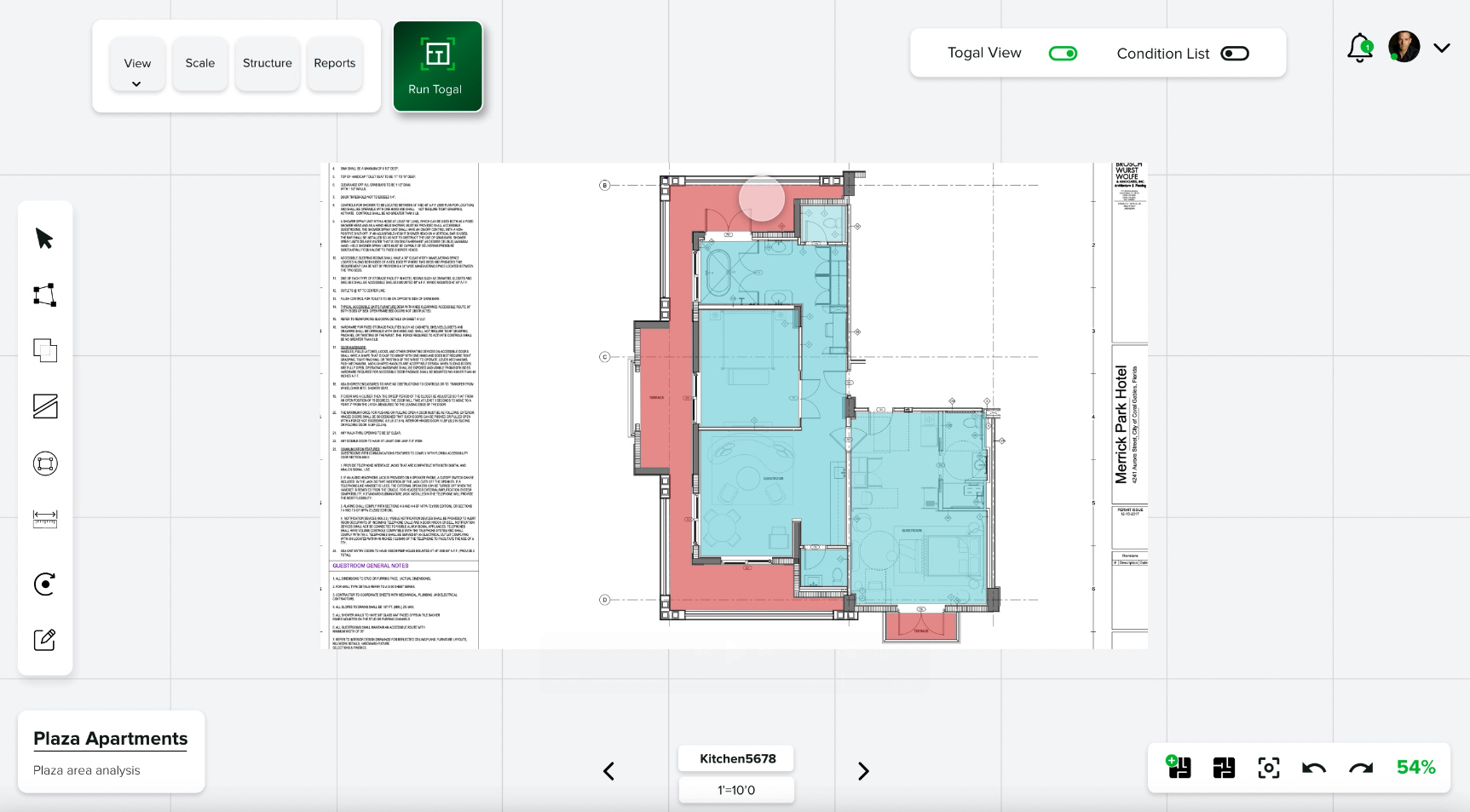
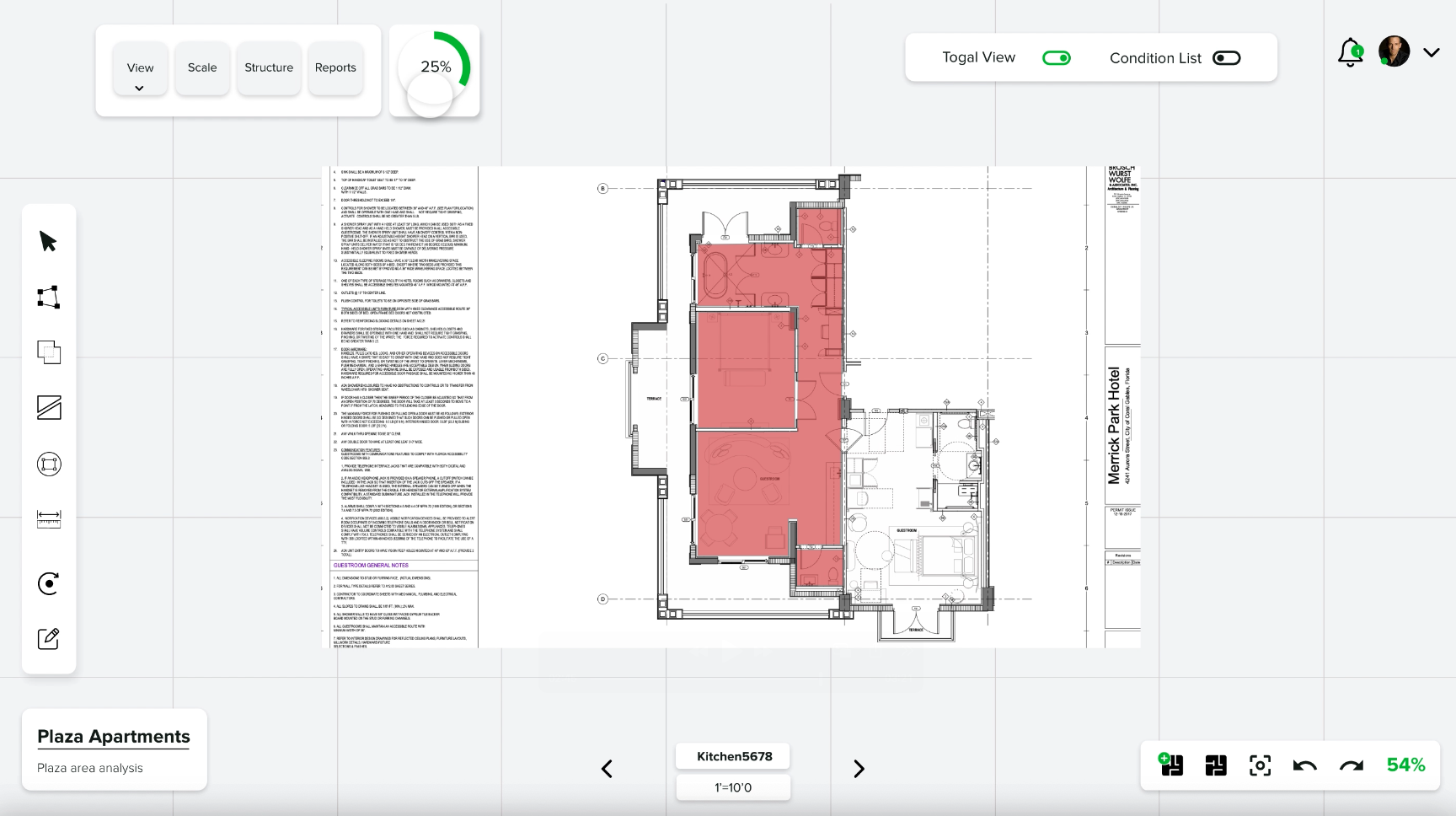
First-class drawing tools beside the AI
When the AI gets a freeform shape wrong, the estimator nudges it instead of redoing it. Override is one click, not a workflow restart.
The whole loop in under a minute
The first and last screens of the day
The workspace gets the headlines, but estimators live just as much in the bookends — the door they walk through every morning, and the gallery they triage their week from. Both inherit the same trust language as the canvas.

- More cross-trade discovery. Optimized for commercial GC. Subs and residential users had a different model of trust we didn’t fully address.
- Confidence visualization, earlier. The color system landed late in the build. Had it been a constraint from week one, several screens would be simpler.
- A real handoff to Excel. We shipped CSV. What estimators wanted was a live, named-range XLSX dropping into existing pricing books.